
La prueba para saber si un PDF es una serie de imágenes empaquetadas en un fichero o si podemos hacer búsquedas en él es sencilla. En Adobe Reader (que es la aplicación que todos tenemos en nuestros ordenadores) hay que pulsar el ratón sobre una página; si se torna azul, entonces es un gráfico (una fotografía electrónica). Otra prueba para confirmarlo es buscar (control F / cmd F) una palabra que sepamos que se encuentra en el PDF. Si la respuesta es No se encontró ninguna coincidencia, entonces es un gráfico (salvo que le hayamos pedido que busque algo que realmente no está).
Si el PDF que nos interesa es una serie de gráficos, es fácil convertirlo en otro en el que se puedan hacer búsquedas, cortar y copiar (cuando cortes y pegues del trabajo de otro acuérdate de citarlo adecuadamente –insistiremos sobre el tema–). Dependiendo del ordenador y del tamaño del PDF puede llevar desde unos pocos segundos a un buen rato (para un libro de 207 páginas a mi iMac –del 2009– le llevó 12 minutos).
Para esta conversión hay que tener el programa Adobe Acrobat. No sirve el Acrobat Reader, lo que es un pequeño problema. Sin embargo, las universidades, por lo general, tienen licencias de campus y en alguna biblioteca o sala de informática habrá un ordenador con el programa bien instalado y en perfecto orden de funcionamiento, es decir, con su licencia correspondiente. Trabaja ahí; no te llevará mucho tiempo modificar los ficheros.
Una vez localizado el ordenador que cumple los requisitos, tan solo hay que abrir el PDF, pulsar en Documento > Reconocimiento de texto OCR > Reconocer texto usando OCR y Aceptar. (Si se tiene un lote de ficheros PDF que se quieren hacer explorables, entonces la opción que se ha de elegir es Reconocer texto en varios archivos usando OCR). Se puede establecer el Lenguaje primario de OCR, pero mi experiencia me ha demostrado que no merece la pena enredar demasiado en esos aspectos: una prueba con un libro multilingüe no produjo problemas.
Dentro de Adobe Acrobat se pulsa Archivo > Propiedades. Cuando se abre la ventana de Propiedades del Documento hay que hacer clic en la pestaña Descripción.
Ahí conviene cumplimentar los datos referentes al Título, el Autor y las Palabras clave. En Asunto recomiendo introducir la información referente a la publicación (datos de la revista o del libro del que procede)
Lo fundamental de estos metadatos es que hacen que el fichero deje de ser un PDF indocumentado, lo cual tiene ventajas posteriores, especialmente si se incorpora a un gestor de PDF como Mendeley o Papers.
La utilidad más aparente es dentro del navegador de Windows, pues tan pronto como se pose el ratón sobre el nombre del fichero, se abrirá un globo rectangular con la información (autor, flecha roja; título, flecha azul; información bibliográfica (asunto), flecha violeta), con lo que veremos a simple vista si es el fichero que buscamos o no.

Afinando el trabajo
Si queremos refinar nuestra labor con el PDF, podemos incorporarle los metadatos. Eso es algo que la mayoría de los editores de PDF olvidan (yo lo he olvidado en las actas de un congreso y todas las separatas informan de que soy su autor. ¡Horror!). De nuevo es algo sencillo de solucionar.Dentro de Adobe Acrobat se pulsa Archivo > Propiedades. Cuando se abre la ventana de Propiedades del Documento hay que hacer clic en la pestaña Descripción.
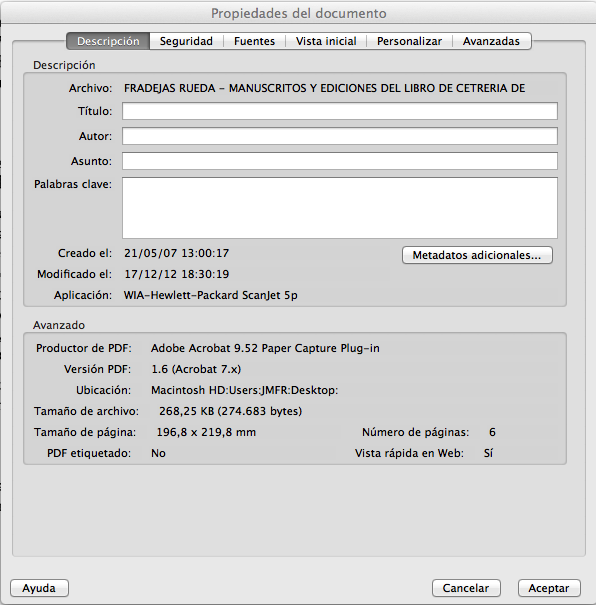 |
| Propiedades de un PDF sin la información de Título, Autor, Asunto ni Palabras clave |
 |
| El mismo fichero con los datos incorporados |
La utilidad más aparente es dentro del navegador de Windows, pues tan pronto como se pose el ratón sobre el nombre del fichero, se abrirá un globo rectangular con la información (autor, flecha roja; título, flecha azul; información bibliográfica (asunto), flecha violeta), con lo que veremos a simple vista si es el fichero que buscamos o no.

No hay comentarios:
Publicar un comentario